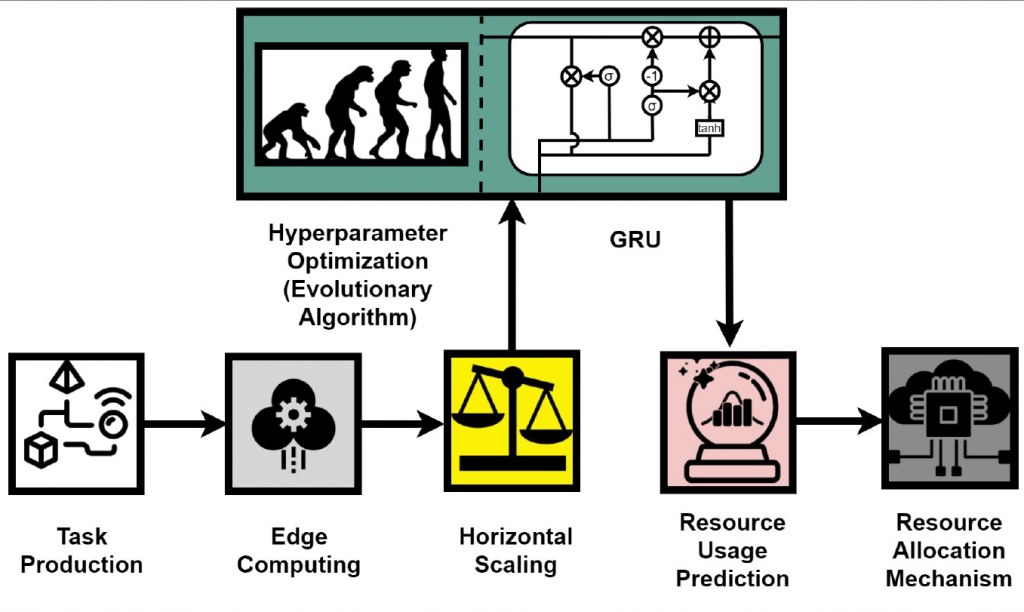
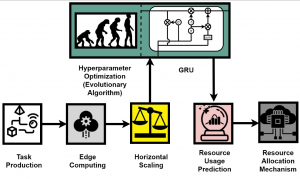
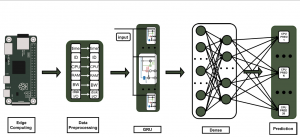
 The management and orchestration of edge computing infrastructures can be improved by predicting the time-evolving resource utilization metrics with an RNN model. Mostly these metrics are CPU, RAM, bandwidth, and disk I/O. The edge computing is characterized by the dynamic behaviour and the heterogeneity of the processing edge nodes combined with constraints implied by the Service Level Agreements (SLAs).
The management and orchestration of edge computing infrastructures can be improved by predicting the time-evolving resource utilization metrics with an RNN model. Mostly these metrics are CPU, RAM, bandwidth, and disk I/O. The edge computing is characterized by the dynamic behaviour and the heterogeneity of the processing edge nodes combined with constraints implied by the Service Level Agreements (SLAs).
The decision making in a dynamic and heterogeneity environment is a difficult process and every available piece of information should be used. The prediction of resource usage, leveraging time series characteristics of historical data, constitutes one of the most valuable pieces of information. It is a strong indicator for the availability of the processing nodes in order to receive further workload or a QoS degradation in next time steps. In this respect, the public available monitoring tools like Prometheus, OpenTSDB, Nagios and InfuxDB can provide the resource metrics in a stream format or in a time series database like PromoQL. These time series databases can be used to extract the historical datasets for the RNN model training.
The dynamic behaviour of edge nodes is due to the fluctuation of application requests and workload. The number of requests per interval time changes during the days and many periodic phenomena can affect it. The heterogeneity means that the edge nodes mostly have different characteristics in memory size and computing power. We can contemplate this heterogeneity taking into consideration the different flavours of Raspberry Pis that are available, coexist and collaborate in an edge infrastructure.
The SLAs put the constraints for the performance of edge nodes in terms of availability, throughput and different types of delays. The edge providers are struggling for the SLAs not be violated. In doing so, they must take timely and optimal decisions regarding the task offloading, resource allocation and proactively fault tolerance.
Author: John Violos | ICCS