Machine Learning (ML) methods can identify patterns that describe humans’ behaviours. This can only happen when the methods are given enough data to train on. Depending on the type of data at hand, these methods can model and be trained to detect distinct behaviours, properties or characteristics of users. Using such models, their owners can then predict what a user may or may not do with high confidence in a future setting. Some of these behaviours can be also described as weaknesses of users (e.g., “When is the user more likely to buy ice-cream or chocolate?”, or “When is the user more likely to default on their loan”) and can help the ML method owner to manipulate users for his advantage (e.g., to make more sales of ice-cream or chocolate, or select more carefully who to give loans and when).
Such ML methods are used in many systems and platforms in our lives: online websites, applications or programs, devices, etc. They facilitate the modelling and prediction of clicks on articles inside or across webpages, clicks on ads, sales of products, etc., the modelling of user selection in different contexts such as consumption of music, audio and video clips, books, clothes, movies and other purchases, and offering recommendations what item to view, read, or buy next. In such examples, and many other settings, users cannot process all possible options available from the platform. Therefore, they get encouraged, or even conditioned to select from within the recommendations and predictions of the ML method.
Typically, training a ML model requires some centralized service (usually cloud-based or data center-based) for collecting, aggregating, and processing all user data and train an ML model. However, this traditional ML paradigm has led to repetitive privacy concerns since users must trust that the central service does not misuse their data for their own purposes and that these entities will also protect the users’ data from cyber hacks or thefts, and other privacy violations that may arise in the future. Thus, a conflicting question arises from this traditional ML paradigm:
How can we preserve or even improve the privacy of users and their data, while still allowing ML model owners the capability to build useful models on such data?
Privacy-Preserving Machine Learning
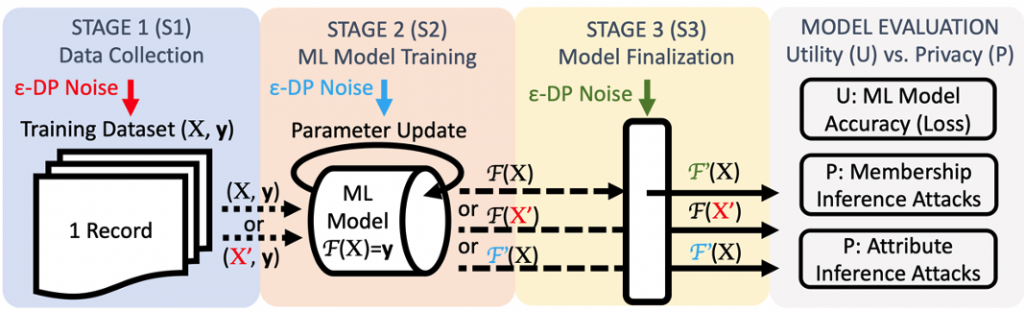
Nowadays, the ML community is fortunate to have new developments in the area of ML, called Privacy-Preserving Machine Learning (PPML). In fact, we have recently investigated [1] this previously stated question, in order to understand the tradeoff between privacy of data and ML model utility. In particular, and assuming the use of Differential Privacy (DP) to protect user data or models, we proposed a framework for comprehensive and systematic evaluation and comparison of DP-enabled ML methods such as Random Forest, Naïve Bayes, Logistic Regression and Neural Networks. The 3-staged framework we proposed is illustrated in the following Figure:
Figure 1: Our instantiation of the proposed methodology, with the three possible Stages that DP noise can be introduced in the ML pipeline to guarantee data privacy, and performance metrics used to assess privacy-utility tradeoff.
Using this framework, we studied how the injection of DP-based noise in the data source, or during the ML modeling, while providing privacy guarantees to the used data, can also impede the utility of the ML model built. We also assessed the performance of an adversary when mounting a model or data inference attack on the trained model or DP-noisy data. We have found that under some conditions with respect to data complexity (number of classes and type of data), model complexity and DP-noise injection, a good tradeoff can be achieved between data privacy and ML model utility [1].
Another main such effort along the lines of PPML is called Federated Learning (FL). Google proposed FL[2] a few years ago as a novel technique for training an ML model, where user data always stay at the edge or at the source (i.e., at the user’s phone, or IoT device). Instead of collecting the data at the server, each user’s device trains its own version of the ML model locally on their data, and only shares this resulted model with the centralized service. All resulted models are collected and aggregated into a single, more powerful model that is distributed back to the users for further such FL rounds until desired convergence is reached. This new paradigm for building ML models has been already used by Google and Apple to train the models used in smartphone keyboards for detecting the next word the user will type, or suggest the right or best emoji to use. More applications of FL can be anticipated in the future, such as in healthcare, where all health-related data can remain at the user’s device while contributing to global models capable of medical diagnostics. Someone could envision similar scenarios with financial or other personal or non-personal data.
Federated Learning as a Service
In this line of work on FL, we have proposed FLaaS, the 1st Federated Learning as a Service system. The system’s design and proof of concept implementation have been published and presented [3], and a patent has also been filed for the system design [4]. In brief, FLaaS makes, among others, the following contributions in FL space, which help Telefonica handle anonymity and privacy with machine learning on user data:
- FLaaS provides high-level and extensible APIs and a Software Development Kit (SDK) for service usage and privacy/permissions management.
- FLaaS enables the collaborative training of ML models across its customers on the same device using APIs, in a federated, secured, and privacy-preserving fashion.
- FLaaS enables the hierarchical construction and exchange of ML models across the network.
- FLaaS can be instantiated in different types of devices and operational environments: mobile phones, home devices, edge nodes, etc.
An illustration of different use cases that can be supported with FLaaS are shown in the following Figure:

Figure 2: Motivating use-cases of FLaaS, involving end-user and edge devices in the FL process. User and edge devices can participate in FL rounds, by building their versions of the ML model on user local data. Using FLaaS, different applications can collaborate to build powerful models on shared data and models, beyond what they could have done independently.
Our FLaaS proof of concept implementation and testing revealed the feasibility of the design and performance benefits on how to enable participating applications to build collaborative ML models in the future FL space.
Privacy-Preserving Federated Learning
While FL allows the users to participate in the ML modeling without sharing their sensitive data, that does not guarantee the user’s complete privacy, since the parameters of the model built can leak sensitive information about the user. For instance, adversarial methods such as Membership Inference and Attribute Inference Attacks can reveal if a particular user was part of the model’s training set or not (e.g., did user X participate in a user study that aims to detect the Alzheimer disease?), or even what values their data had at the time they were used in the modelling. DP has been proposed as a way to offer a privacy guarantee from such type of attacks. As mentioned earlier, DP is a technique that introduces noise to the model’s parameters to protect the user’s privacy, but consequently sacrificing the model’s accuracy.
In order to address such attacks, while training a model using FL, we have recently proposed PPFL, the 1st Privacy-Preserving Federated Learning framework [5], to protect the user’s data modelling during the FL process. Also, a patent has been filed for this system design [6]. In particular, and leveraging the widespread presence of Trusted Execution Environments (TEEs) in high-end and mobile devices, we utilize TEEs on mobile clients for local FL training, and on servers for secure FL aggregation, so that the model and its updates (one update per user per FL round) are hidden from adversaries. Unfortunately, current TEEs are usually of limited memory and cannot train the full ML model in TEE memory. Thus, we leverage greedy layer-wise training to train each model’s layer inside the trusted area until the model’s convergence. An overview of PPFL’s architecture is shown in the following Figure:
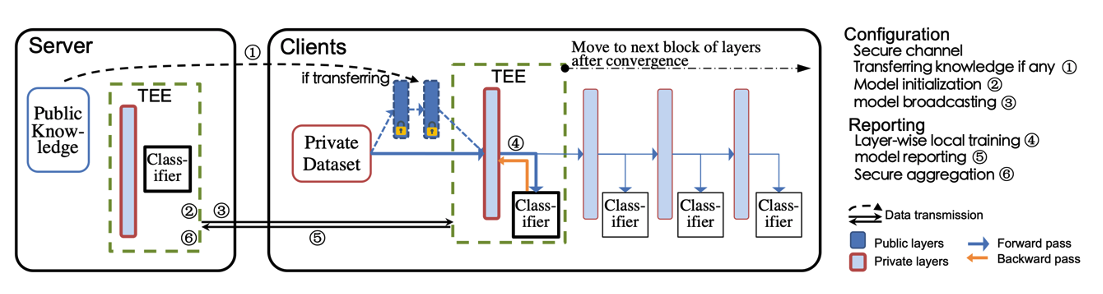
Figure 3: A schematic diagram of the PPFL framework, illustrating the greedy, layer-based FL training. The idea is that PPFL loads into TEE memory of the mobile client one layer of the model at a time, trains it (along with its previous layers in secured storage), and transmits it to the server for secured aggregation across all clients.
Our evaluation of the framework’s performance showed that PPFL can significantly improve privacy while incurring small system overheads at the client-side. In particular, PPFL can successfully defend the trained model against data reconstruction, attribute inference, and membership inference attacks. Furthermore, it can achieve comparable model utility with almost half the communication rounds needed in normal FL settings, and a similar amount of network traffic compared to the standard FL of a complete model. This is achieved while only introducing up to 15% extra CPU computation time, 18% extra memory usage, and 21% energy consumption overhead in PPFL’s client-side [5].
Conclusion
Several challenges still exist when training ML models in an FL fashion. Each user’s data reflect only the given client’s usage of the device and view of the problem, rather than that of the whole population distribution. Therefore, many users are need to participate to get a good FL model. Unfortunately, the massively distributed nature of FL makes communication and device participating unpredictable, as we cannot assume that user devices will always be online, and with fast and stable connectivity to send and receive updates of the model under training. Moreover, we anticipate that every device can be different, introducing high device heterogeneity in the problem, with various OSes, hardware characteristics and different processing and memory capabilities. Also, we anticipate high heterogeneity with respect to data across users and devices. Finally, privacy is still a pending concern in FL, as more advanced data and model attacks are expected to surface. Thus, many more improvements will have to be made in FL, in order to truly realize the privacy-by-design ML frameworks that can be used in the future and provide high utility of ML models, while preserving the privacy and even anonymity of the users and data owners participating in the modelling.
References
[1] Benjamin Zi Hao Zhao, Mohamed Ali Kaafar, Nicolas Kourtellis. Not one but many Tradeoffs: Privacy Vs. Utility in Differentially Private Machine Learning. Proceedings of the ACM SIGSAC Conference on Cloud Computing Security Workshop (CCSW), 2020.
[2] H. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, Blaise Agüera y Arcas. Communication-Efficient Learning of Deep Networks from Decentralized Data. Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), 2017.
[3] N. Kourtellis, K. Katevas and D. Perino. FLaaS: Federated Learning as a Service. Proceedings of the ACM Workshop on Distributed Machine Learning (DistributedML), 2020.
[4] N. Kourtellis, K. Katevas and D. Perino. FLaaS: Federated Learning as a Service. Patent Filed, 2020.
[5] Fan Mo, Hamed Haddadi, Kleomenis Katevas, Eduard Marin, Diego Perino, Nicolas Kourtellis. PPFL: Privacy-preserving Federated Learning with Trusted Execution Environments. Proceedings of the 19th Annual International Conference on Mobile Systems, Applications, and Services (MobiSys), 2021.
[6] Fan Mo, Kleomenis Katevas, Eduard Marin, Diego Perino, Nicolas Kourtellis. Federated Learning for Preserving Privacy. Patent Filed, 2021.
Short Bio
Nicolas Kourtellis holds a PhD in Computer Science & Engineering from the University of South Florida, USA (2012). He has done research @Yahoo Labs, USA & @Telefonica Research, Spain, on online user privacy and behaviour modelling, Internet measurements and distributed systems, with 70+ published peer-reviewed papers. Lately, he focuses on CyberPrivacy (Privacy-preserving Machine Learning (ML) and Federated Learning on the edge, user online privacy and PII leaks), etc.) and CyberSafety (modelling and detecting abusive, inappropriate or fraudulent content on social media using data mining and ML methods, and how they can be applied on the edge on user-owned or network devices). He has served in many technical program committees of top conferences and journals (WWW, KDD, CIKM, ECML- PKDD, TKDD, TKDE, TPDS, etc.). The aforementioned work has been partially funded by the European Commission, with the following projects: Concordia (830927), Accordion (871793) and Pimcity (871370).